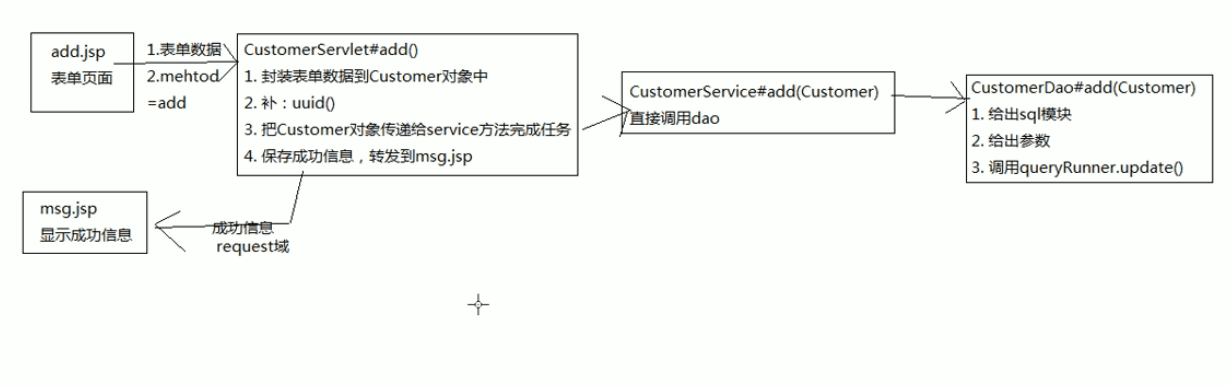
XML入门:使用JAXP遍历节点
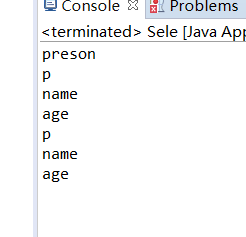
如: 把xml中,所有元素名称都打印出来
package cn.xtnotes.jaxp;
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.w3c.dom.Text;
import org.xml.sax.SAXException;
public class Sele {
public static void main(String[] args) throws Exception {
//SelectALL();
//selectSin();
//addSex();
//modifySex();
del();
}
//把xml中,所有元素名称都打印出来
public static void lis() throws Exception {
/*
* * 1.创建解析器工程
* 2.根据解析工厂创建解析器
* 3.解析xml,返回document
*
* ====使用递归
* 4.得到根节点
* 5.得到根节点的子节点
* 6.得到根节点的子节点的子节点
*/
//创建解析器工厂
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
//创建解析器
DocumentBuilder builder = builderFactory.newDocumentBuilder();
//解析xml,得到document
Document document = builder.parse("src/person.xml");
//编写一个方法实现遍历操作
list1(document);
}
//递归遍历方法
private static void list1(Node node) {
//判断是元素类型时在打印 否则连带空格和换行都会打印
if(node.getNodeType() == Node.ELEMENT_NODE) {
System.out.println(node.getNodeName());
}
//得到第一层子节点
NodeList list = node.getChildNodes();
//遍历list
for(int i=0;i<list.getLength();i++) {
//得到每一个节点
Node node1 = list.item(i);
//继续得到node1的子节点
list1(node1);
}
}
}
阅读剩余
版权声明:
作者:Tin
链接:http://www.tinstu.com/705.html
文章版权归作者所有,未经允许请勿转载。
THE END