ActiveMQ:Zookeeper和Replicated LevelDB集群部署
集群部署
三种集群方式
- 基于shareFileSystem共享文件系统(KahaDB)
- 基于可复制的LevelDB (介绍这种)
- 基于JDBC
原理
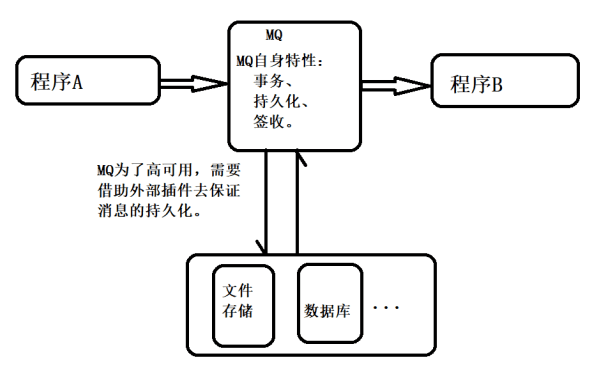
引入消息中间件后如何保证其高可用
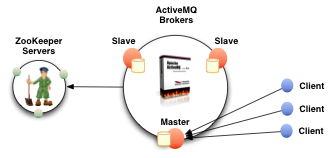
基于zookeeper和LevelDB搭建ActiveMQ集群。集群仅提供主备方式的高可用集群功能,避免单点故障。
官方文档介绍:https://activemq.apache.org/replicated-leveldb-store.html
它使用Apache ZooKeeper来协调集群中的哪个节点成为主节点。选出的主代理节点启动并接受客户端连接。其他节点进入从模式并连接主节点并同步它们的持久状态/w。从节点不接受客户端连接。所有持久性操作都复制到连接的从站。如果 master 死了,最新更新的 slave 将被提升为 master。故障节点恢复后会重新加入集群并链接master进入slave模式!
所有需要同步的消息操作都将等待存储状态被复制到其他法定节点操作完成才能完成。因此,如果您配置存储replicas="3"则法定大小为(3/2+1)=2. master将更新存储在本地,并等待其他1个slave存储更新,然后报告成功。另一种思考方式是,存储将对法定数量的复制节点进行同步复制,并将异步复制复制到任何其他节点。
有一个node要作为观察者存在,当一个新的master被选中,你需要至少保障一个法定node在线以能够找到拥有最新状态的node,这个node才可以成为新的master.
因此,建议您使用至少 3 个副本节点运行,这样您就可以在不中断服务的情况下关闭其中的一个
步骤
1.先配置好zookeeper集群:https://www.tinstu.com/1749.html
2.可以使用一台服务器的不同端口模拟集群 , 修改各个地方的端口就好了
使用三个已经搭建好zookeeper集群的服务器进行搭建
(1)三个云服务安装好activeMQ
(2)将三个ActiveMQ的brokername改为一样的 在conf/activemq.xml 中修改

(3)3个节点的持久化配置 将默认的kahaDB 修改为以下配置, 在conf/activemq.xml 中修改
<!--
<persistenceAdapter>
<kahaDB directory="${activemq.data}/kahadb"/>
</persistenceAdapter>
-->
<persistenceAdapter>
<replicatedLevelDB
directory="${activemq.data}/leveldb"
replicas="3"
bind="tcp://0.0.0.0:63631"
zkAddress="120.48.39.100:2181,180.76.106.99:2181,152.136.194.161:2181" //zookeeper的地址
hostname="152.136.194.161" //本机ip
sync="local_disk"
zkPath="/activemq/levedb-stores"/>
</persistenceAdapter>(4)zk集群成功启动运行的前提下,启动这个三个activeMQ节点,链接任意一个zookeeper的客户端

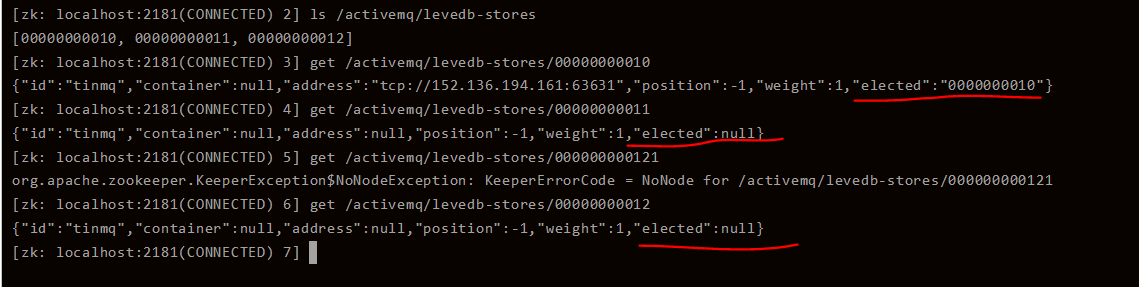
3.状态查看 get /activemq/levedb-stores/00000000010
elected不为空的节点就是Master,其他两个节点都是Slave
Replicated LevelDB集群故障迁移和验证
因为ActiveMQ客户端只能和master的Broker进行链接,所以我只能打开其中一个activemq的控制台,剩余两个都打不开,客户端链接Broker应该使用failover(失败转移)

当一个zookeeper或一个activeMQ节点挂掉,ActiveMQ服务仍然正常运转,如果仅剩一个activeMQ,由于不能选举master,所以activeMQ不能正常运转
如果zookeeper仅剩一个节点,不过activeMQ各个节点存活,activeMQ也不能正常提供服务(activeMQ集群的高可用,依赖于zookeeper的高可用)
当干掉activeMQ的master后,zookeeper会再选一个master
(md,我测试的没选出来)